Building a prototype Javascript engine for MongoDB
05 Sep 2015
This past summer, during my internship at MongoDB, I worked with my partner, Margaret Stephenson, and developed a prototype Javascript engine that significantly improved performance of the $where operator in MongoDB. We also applied certain heuristical optimizations to allow $where to utilize Collection indexes where possible.
$where
MongoDB has a few tricks up its sleeves when it comes to database queries. A unique feature of Mongo is its $where operator. $where lets a user query a database by passing in a custom Javascript function or expression.
db.foo.find({$where: "function() { return this.a == 1; }"})
Essentially, each Document in a particular Collection is binded to the scope of the function or expression (the this variable takes on the value of the Document in question), which is then evaluated for a boolean value. The query succeeds if the evaluation is true, and that particular Document is returned in the response.
This opens up a wide range of possibilities for queries that cannot be expressed simply through Mongo’s query language. For example, you cannot perform intra-Document comparisons with query language, but that can easily be achieved through $where.
db.foo.find({$where: "function() { return this.a == this.b; }"})
However, $where has traditionally yielded extremely poor performance compared to Mongo’s native query language, often times 2-3 magnitudes slower when performing similar queries.
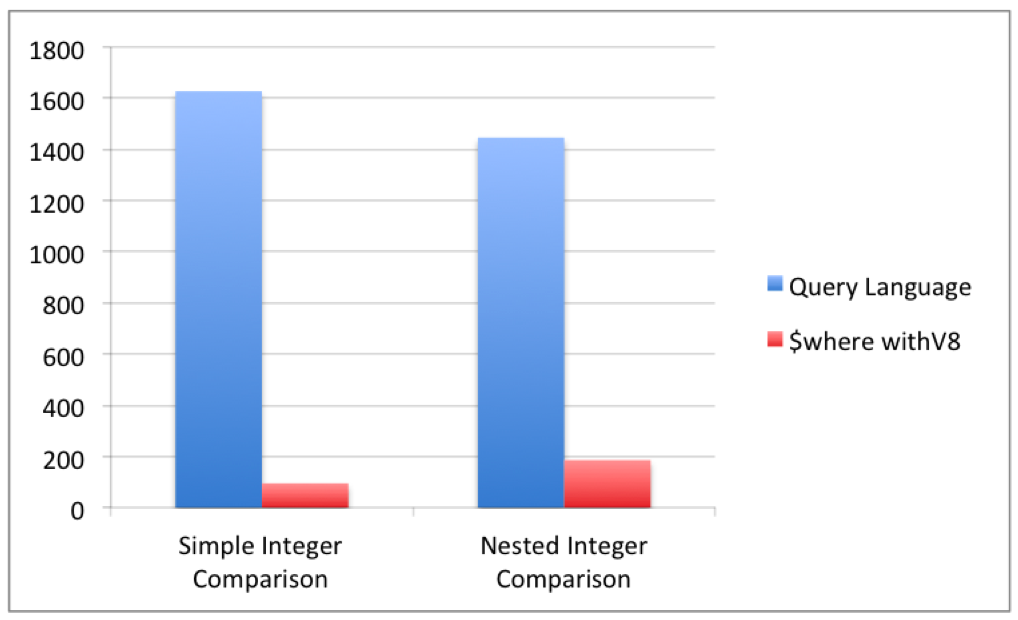
The chart below shows a few performance tests querying for similar Documents using query language and $where. The simple integer test measured performance in database OPS, performed against an unindexed Collection of 1000 Documents of the form { x : i | 0 < i < 1000 }
// Query Language
db.foo.find({x:1});
// $where with V8
db.foo.find({$where: "function() {
return this.x === 1;
}"})
Before we look at why this performance difference exists, let’s go over how data is stored in Mongo.
BSON
Data is stored as BSON Documents in MongoDB. BSON stands for Binary JSON. BSON is a binary encoded serialization of JSON like Documents. In short, it is similar to JSON, but contains additional information that allows for the representation of data types that are not part of the JSON specification.
An important thing to note is that Mongo’s native query language operates directly on the BSON Documents present in the targeted Collection.
V8 and SpiderMonkey
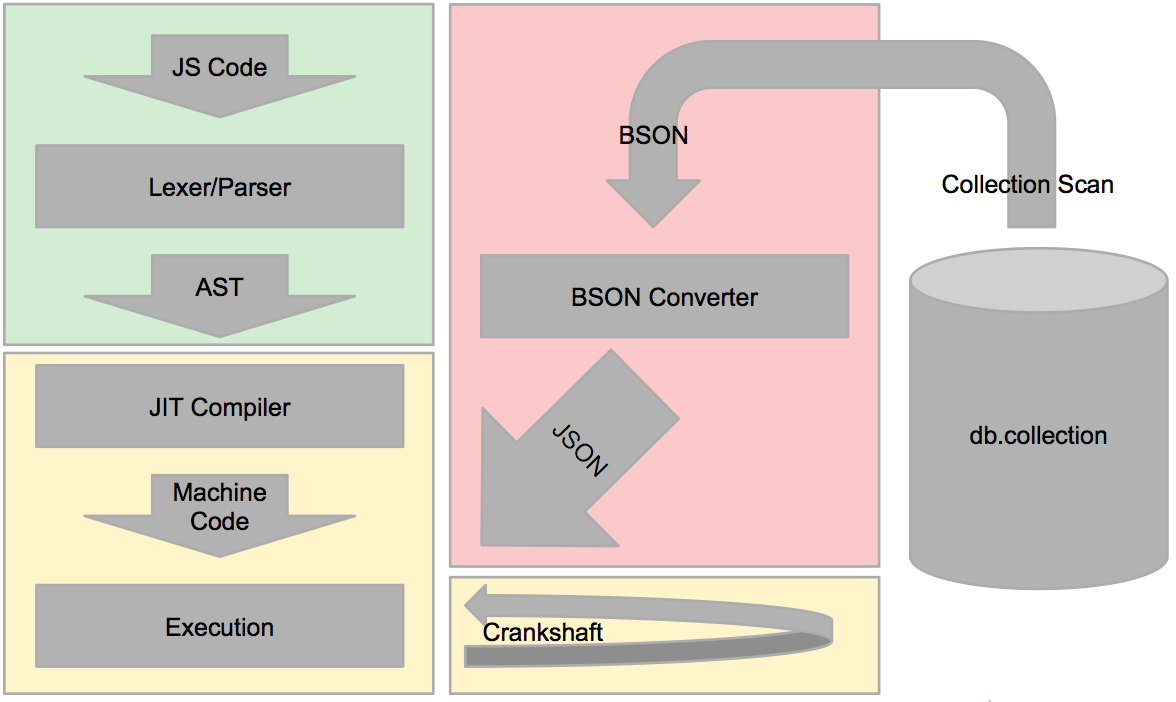
The underlying magic of $where exists in the Javascript engines that are used by Mongo. Depending on the release version of Mongo that is being used, the engine will either be Google’s V8 or Mozilla’s SpiderMonkey. These engines evaluate the provided $where Javascript code. For convenience sake, I’ll mainly cover V8 (also because V8 was the default engine included with Mongo when we began our internship project), but similar problems exist in both.
One of the main reasons why $where is so slow compared to Mongo’s native query language is because V8 and SpiderMonkey do not natively know how to interact with BSON data. Therefore, each Document that is being evaluated in a Collection must first be converted to JSON before being binded to the evaluation scope. Although the overhead of this conversion may not seem like much for a single Document, $where evaluates every single Document in the designated Collection. For large Collections, this BSON to JSON conversion becomes a huge resource hog when taken into consideration that it is done through a Collection scan.
V8 is a highly optimized Javascript “interpreter.” However, to call it an interpreter at all is quite the misnomer because V8 utilizes JIT (just-in-time) compilation to perform on-the-fly compilation of Javascript code to machine code. In fact, V8 is composed of not one, but two compilers. The first compiler does a fast pass over the Javascript code. There is very little optimization going on in this first compilation step. However, there is a second compiler, called Crankshaft, that identifies heavily used blocks of code that can be optimized, and recompiles those chunks of code using various optimization methods. While JIT compilation and these optimizations are very well suited for long, web-facing Javascript programs, it is unlikely that they are very useful for short simple Javascript expressions expected by $where. In fact, the overhead of performing these compilations and optimizations may be detrimental, overall.
Here’s a diagram of what a $where operation would look like through V8. The red part yields the biggest performance overhead and the yellow parts are also unnecessary performance hogs.
tinyJS
Taking the performance problems behind $where into consideration, Margaret and I created a prototype Javascript engine (which we ended up naming tinyJS) with two main features in mind:
- It would include the capability to operate directly on BSON Documents, thus eliminating the performance overhead of the BSON to JSON conversion.
- It would omit unnecessary compilation and optimization stages
A short intro to compilers
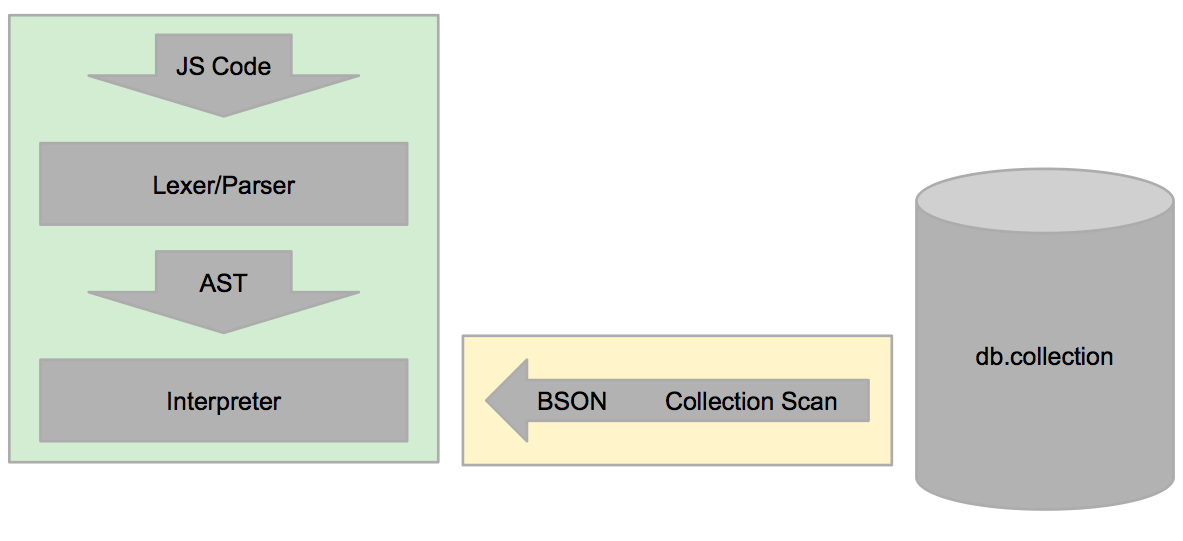
Seems straightforward enough (right?). Having had zero prior experience with compilers/interpreters between the two of us, we spent the first few weeks of our internship combing through a compilers textbook to learn how to go about starting this project. It became clear that the implementation of this engine would fall into a three distinct parts:
- Lexer
- Parser
- Interpreter/Evaluator
Here’s a simple diagram of what our finished implementation would look like:
Lexer
In writing a Javascript interpreter, the first step was to separate the stream of Javascript code into various tokens. Known as lexing, or tokenization, we used a tool called Ragel that allowed us to define various patterns for each keyword or literal that was part of the Javascript language. Ragel would take these patterns and compile them into fast C state-machine code. Traditionally, compilers textbooks often prescribe a tool called Lex to do the lexing, but Ragel seemed like a cool technology to explore so we used that instead.
Parser
After lexing, the parsing stage effectively creates some interpretable representation of the Javascript code. Two particular data structures dominate this phase of compilation/interpretation: parse trees and abstract syntax trees (AST). These two trees are almost the same, with the exception being that parse trees generate a full representation of the provided code, whereas ASTs retain only the necessary information in order for the compiler/interpreter to do its job. In our case, we were only interested in the AST of provided Javascript code.
An important thing to note is the precedence of the tokens. Tokens can be operators or operands, and certain operators will have precedence over other operators. In the context of programming languages such as Javascript, the inclusion of paranthesis in the code can also change normal operation precedence as well. These precedence rules determine the shape and structure of each generated AST. So before we could go on to create an AST generator, we had to figure out how these precedence rules were determined.
Context Free Grammars
In formal language theory, a context free grammar is a set of production rules in the form of
`NT -> RHS, where RHS is a string of terminal, `T, and/or non-terminal, `NT symbols, and RHS can be empty or optional
A language that can be described via a set of context free grammar rules is a language in which each non-terminal symbol ``NT can be replaced with its respective right hand side RHS`. It is considered context free because this replacement can be applied no matter where the non-terminal is in the input.
We created a subset of production rules that covered a significant chunk of the Javascript language. In consideration of time, we did not seek to create a full set of rules that covered all of Javascript (since the purpose of our project was to simply prove that, in the specific case of $where, our engine could be faster than V8 or SpiderMonkey, we did not need to cover the entire set of Javascript production rules).
Back to Parsing
The set of context free grammar rules determines the precedence of tokens when generating the parse tree. At this stage of the compilation/interpretation process, the grammar rules are used by a parser to generate the Abstract Syntax Tree for the provided Javascript input.
Delving deeper into compiler theory, there are several parser generators that take in a set of grammar rules to automatically generate a parser for that particular grammar. Often, the provided grammars are in the form of LL or LR grammars (or some derived form of LL and LR, such as LALR), which (after being passed through the automatic parser generator) lead to a type of bottom-up, table driven parser. A common parser generator that takes in a grammar and generates a LALR parser is YACC.
Although we did toy around with the idea of using table driven parsers, because our set of Javascript grammar rules was but a subset of the full Javascript language, we decided to forego using YACC or other table driven parser generators. Instead, we went wrote our own recursive descent parser based on our subset of the Javascript grammar. Essentially, each non-terminal symbol/token had its right hand sides defined in its own parser method, which recursively calls other non-terminal methods until the entirety of the Javascript input is resolved. These methods attempt to match the provided input tokens with our subset of Javascript grammar rules, constructing an AST with each matched symbol/pattern. Although the resulting parser code was not and never will be as clean or optimized as a table driven parser, it allowed us to easily modify our grammar and parser as the project progressed. At the end of it all, each Javascript function/expression passed through the $where operator would be translated into an AST.
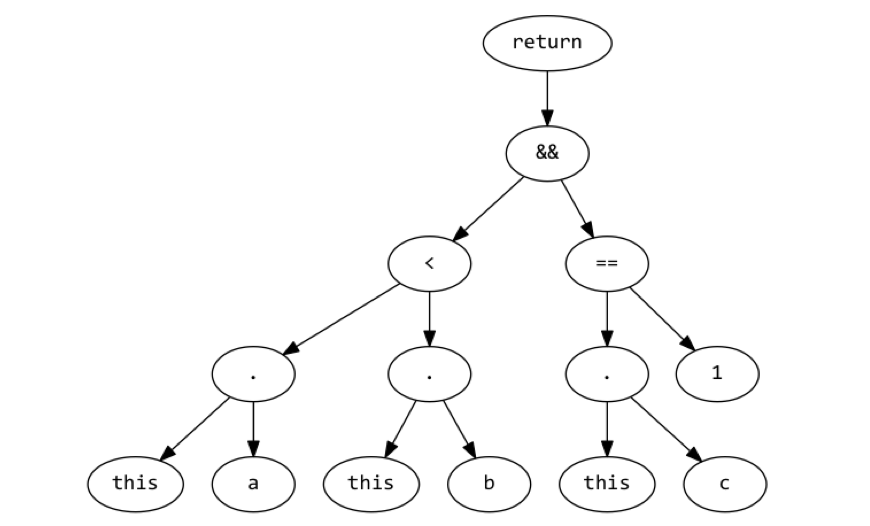
The following function would have an AST as follows:
function() {
return ((this.a < this.b) && (this.c == 1));
}
Interpreter/Evaluator
After the AST is created, the interpretation stage traverses the tree and evaluates each node. Because the precedence of the tokens were taken into account during the creation of the AST, a simple post-order traversal of the tree would yield the correct results for the evaluation stage.
The generated AST consists of operators and operands. Each operand symbol would simply return its own value, whereas each operator would evaluate its respective operands. Every operator and operand was trivial to implement, with the exception of Document accessors. We made sure to use the native BSON APIs when accessing Document properties, thus eliminating the previously mentioned overhead of BSON to JSON conversion. Each Document in the queried Collection is binded to the scope of the AST and the AST is evaluated for a boolean return value. The boolean value indicates whether or not the Document in question matches the provided $where query.
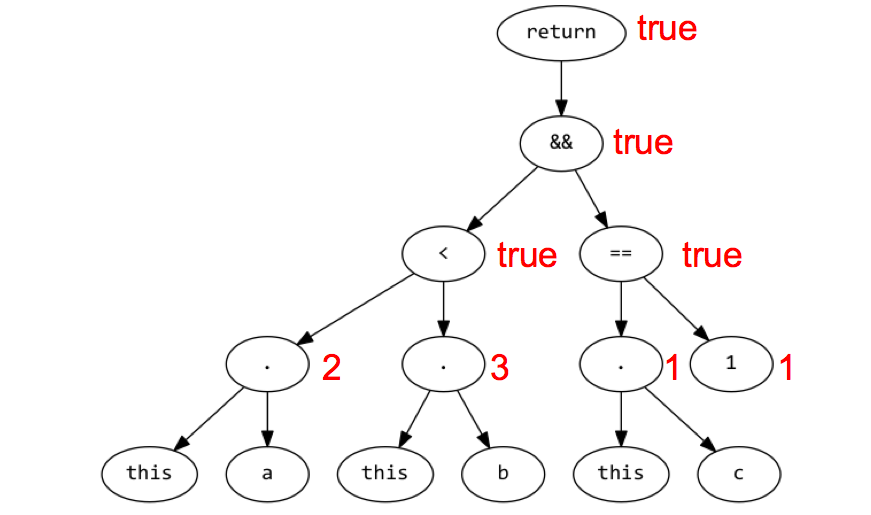
The following function
function() {
return ((this.a < this.b) && (this.c == 1));
}
evaluated against a Document with the properties {"a" : 2, "b" : 3, "c" : 1}:
Preliminary Results
So how did our prototype engine fare against V8 and SpiderMonkey? We ran some preliminary tests against the two existing Javascript engines to see whether or not performance improved.
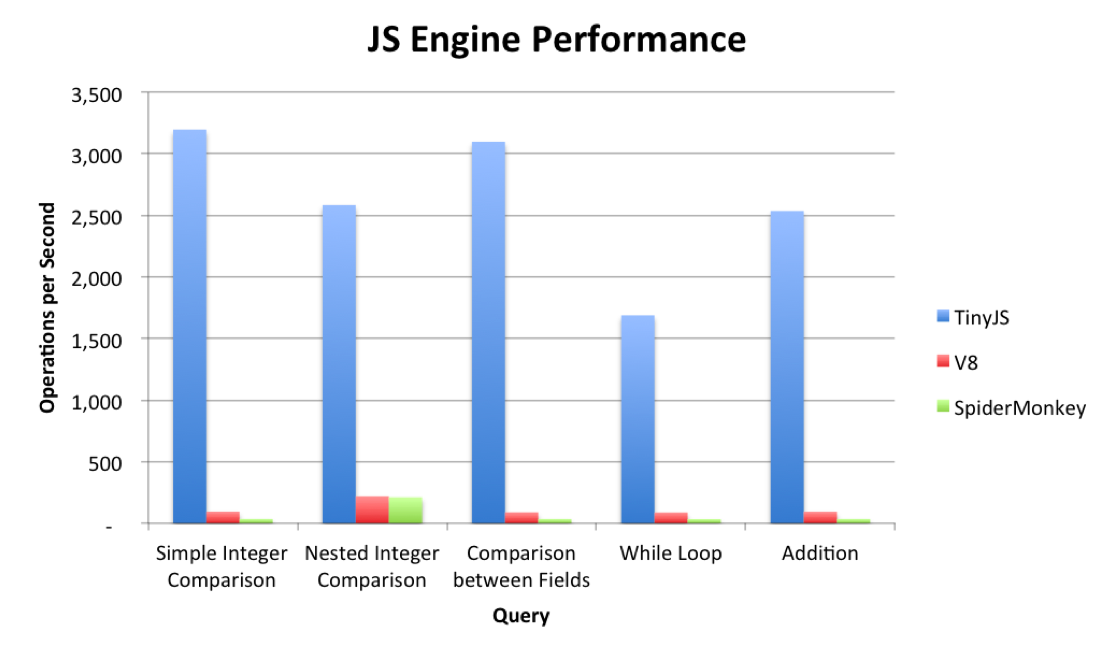
Simple Integer Comparison
Unindexed Collection of 1000 Documents of the form { x : i | 0 < i < 1000 }
db.Collection.find({$where: "function() {
return this.x === 1;
}"})
33.6x faster than V8 91.3x faster than SpiderMonkey
Nested Integer Comparison
Unindexed Collection of 13 objects, each with 4 nested levels of 13 fields
db.Collection.find({$where: "function() {
return this.d.c.b.a === 1;
}"})
11.8x faster than V8 12.2x faster than SpiderMonkey
Comparison Between Fields
Unindexed Collection of 40,000 Documents of the form { x: i, y: j | 0 < i, j < 2 }
db.Collection.find({$where: "function() {
return this.x > this.y;
}"})
34.8x faster than V8 88.5x faster than SpiderMonkey
While Loop
Unindexed Collection of 1000 Documents of the form { x: i | 0 < i < 1000 }
db.Collection.find({$where: "function() {
i = 0; x = 32;
while (i < 1) {
i = i + 1;
x = x + 1;
}
return this.x == x;
}"})
19.2x faster than V8 49.6x faster than SpiderMonkey
Addition
Unindexed Collection of 1000 Documents of the form { x: i | 0 < i < 1000 }
db.Collection.find({$where: "function() {
return this.x === (1 + 5) - 2;
}"})
27.0x faster than V8 72.4x faster than SpiderMonkey
Can we do better?
However, Mongo’s native query language still outperforms $where queries. A main reason for this is because the native query language takes into account Collection indexes and performs index scans instead of Collection scans wherever possible. This is a simple database query technique that yields huge performance gains.
The last few weeks of our internships were spent trying to implement some type of indexing capability to $where. Since the range of possible $where queries is so large, it is quite a hard problem to tackle (finding all possible optimizations in a provided query is not a trivial task). However, based on a few simple heuristics about the use cases of $where, we were able to identify a few situations which could be optimized.
Mongo’s native query language also builds a tree of sorts that determines which operations to perform (let’s call this the Mongo tree). $where is actually an operator within that tree. As such, if we could identify parts of the $where AST (the tinyJS tree) that are expressable in Mongo’s query language, we could take advantage of potentially indexable queries. By identifying portions of our generated $where AST that performed simple Document property comparisons (i.e. comparisons that can be expressed in query language), we can actually prune our AST and restructure the Mongo tree to include those Document property comparisons. Here’s an example:
db.foo.find({$where: function() {return this.a == this.b && this.c < 1;}})
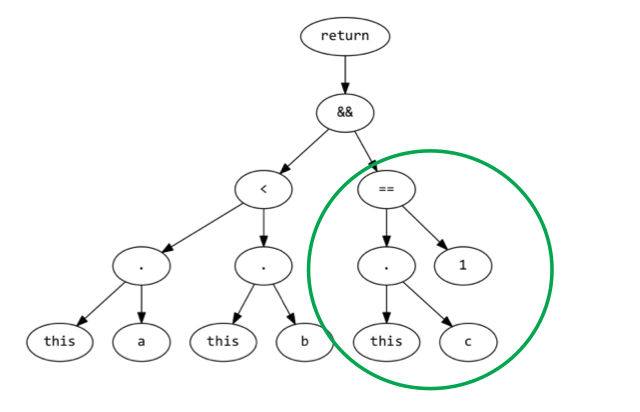
The above query can be restructured to the following:
db.foo.find({$and:[
{c: {$lt:1}},
{$where: function() {return this.a == this.b;}}
]})
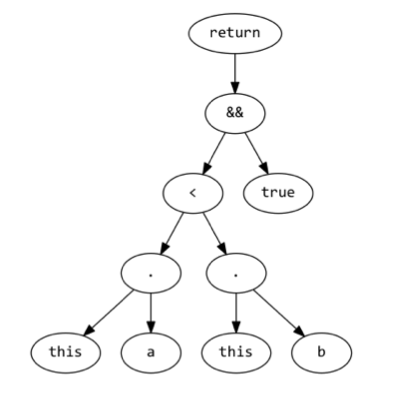
The inclusion of the {c: {$lt:1}} comparison in the Mongo tree will allow Mongo’s query planner to take advantage of Collection indexes (if foo has a Collection index on the c property).
Here’s a diagram of our engine with these optimizations in place:
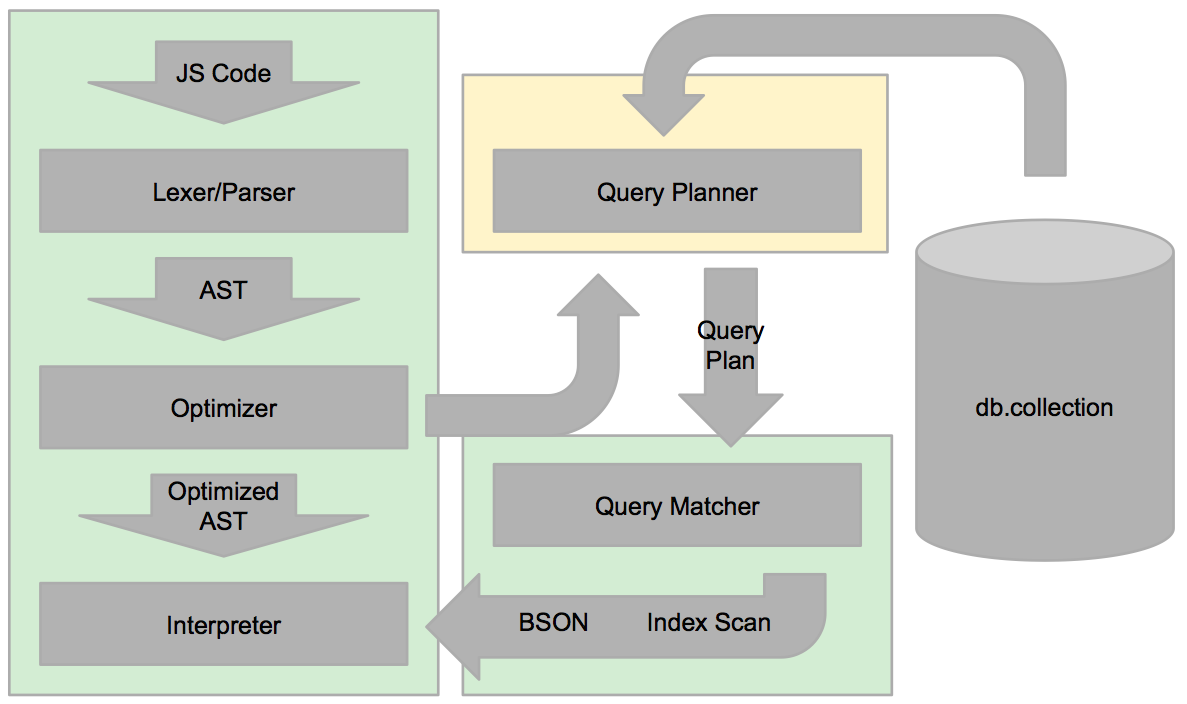
By implementing this pruning and restructuring optimization, we were able to achieve considerably faster performance with $where when Collections were indexed properly. Here is one test we performed:
Queries run on 5000000 Documents of the form { x: i | 0 < i < 5000000 }
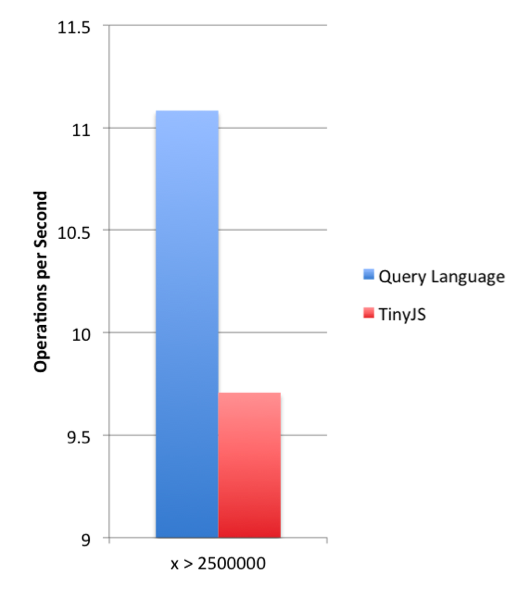
In this particular test, tinyJS yielded performance comparable to Mongo’s native query language, in the same order of magnitude (note that the vertical axis of the above chart does not start at zero).
Epilogue
By the conclusion of our internship, we were able to demonstrate that V8 and SpiderMonkey can be improved upon in the very specific use case of MongoDB’s $where operator. However, our work is far from complete. At its core, tinyJS is just a prototype project, a proof-of-concept meant to demonstrate the possibilities of running a custom solution. The grammar is incomplete, and without a complete Javascript grammar, it is definitely not production ready. With more time, the lexer and parser can be rewritten to support the full set of Javascript grammars, utilizing better parsers than our naive recursive descent parser. However, in the span of ten weeks, we learned a lot about how compilers and interpreters work, and developed a really fast implementation of a working Javascript engine. And there’s just something really cool about that.
Huge shoutout to Margaret for being an amazing internship partner and friend. Big thanks to our mentors, Adam Midvidy and Eliot Horowitz for helping us through this awesome project.